|
A high-performance general-purpose compute library
|
|
A high-performance general-purpose compute library
|
The ArrayFire library offers JIT (Just In Time) compiling for elementwise arithmetic operations. This includes trigonometric functions, comparisons, and element-wise operations.
At runtime, ArrayFire aggregates these function calls using an Abstract Syntax Tree (AST) data structure such that whenever a JIT-supported function is called, it is added into the AST for a given variable instance. The AST of the variable is computed if one of the following conditions is met:
When the above occurs, and the variable needs to be evaluated, the functions and variables in the AST data structure are used to create a single kernel. This is done by creating a customized kernel on-the-fly that is made up of all the functions in the AST. The customized function is then executed.
This JIT compilation technique has multiple benefits:
The above code computes the value of π using a Monte-Carlo simulation where points are randomly generated within the unit square. Each point is tested to see if it is within the unit circle. The ratio of points within the circle and square approximate the value π. The accuracy of π improves as the number of samples is increased, which motivates using additional samples.
There are two implementations above:
Specifically, as JIT is an integral feature of the ArrayFire library, it cannot simply be turned on and off. The only way for a programmer to sidestep the JIT operations is to manually force the evaluation of expressions. This is done in the non-JIT-supported implementation.
Timing these two implementations results in the following performance benchmark:
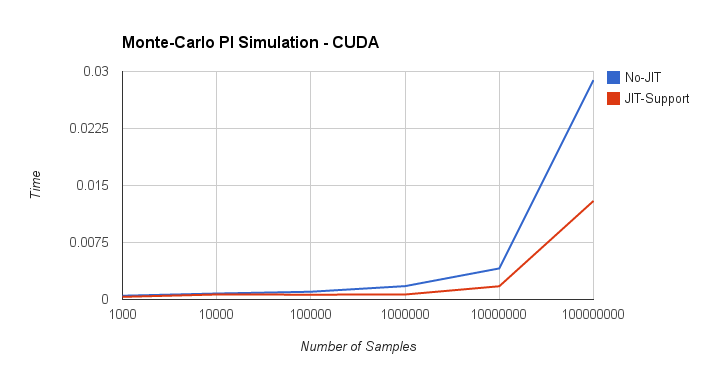
The above figure depicts the execution time (abscissa) as a function of the number of samples (ordinate) for the two implementations discussed above.
When the number of samples is small, the execution time of pi_no_jit is dominated by the launch of multiple kernels and the execution time pi_jit is dominated by on-the-fly compilation of the JIT code required to launch a single kernel. Even with this JIT compilation time, pi_jit outperforms pi_no_jit by 1.4-2.0X for smaller sample sizes.
When the number of samples is large, both the kernel launch overhead and the JIT code creation are no longer the limiting factors – the kernel’s computational load dominates the execution time. Here, the pi_jit outperforms pi_no_jit by 2.0-2.7X.
The number of applications that benefit from the JIT code generation is significant. The actual performance benefits are also application-dependent.